在了解了红黑树的基本概念之后,接下来我们详细了解一下红黑树的插入操作的几种场景
默认规定
对于红黑树而言,需要默认遵守如下两个规定
- 插入节点一定是红色(为了代码简化,默认黑色节点维持平衡)
- 插入操作都是在叶子节点执行
所有场景
根据前面的规定的插入操作,我们可以将全部的插入场景列举出来,将确定的场景在后面标号为(n)
- 将插入节点self称之为:
(s) - 将父亲节点parent称之为:
(p) - 将祖父节点grandfather称之为:
(g) - 将叔叔节点uncle称之为:
(u)
如下:
首先根据父节点颜色区分:
如果插入节点(s)的父节点(p)是黑色的 (1)
- 那么插入节点(s)什么都不做,维持平衡
如果插入节点(s)的父节点(p)是红色的
- 那么平衡破坏,需要进一步调整
然后根据叔叔节点的颜色区分
现在假设所有的插入操作,父节点(p)都是红色的,那么得出其祖父节点(g)一定是黑色的。 这时候叔叔节点(u)的颜色是红色或者黑色。 那么场景如下:
如果插入节点的叔叔节点(u)是红色的 (2)
- 那么将关注节点的父节点(p),叔叔节点(u)的颜色都设置为黑色
- 然后将关注节点的祖父节点(g)设置为红色.(维持红黑树的颜色)
- 将关注节点转换成祖父节点(g)
- 进一步调整(迭代)
这里进一步调整后,我们可以知道从自身修改为祖父节点(g)之后,情况肯定会发生改变,所以代码需要迭代来确定下一步动作
如果插入节点的叔叔节点(u)是黑色的
- 那么需要进一步调整
再根据插入节点相对于父节点(p)的位置区分
根据上面的统计,目前红黑树的已知现状为:
插入节点本身是红色的,插入节点的父节点(p)是红色的,插入节点的叔叔节点(u)是黑色的,插入节点的祖父节点(g)是黑色的,但是对于插入节点而言,不清楚其位于父节点(p)的左子树还是右子树
如果插入节点属于父节点(p)的右子树(3)
- 那么将关注节点设置为父节点(p)
- 然后将父节点(p)进行左旋。也就是让父节点(p)和父节点(p)的右节点断开,改变其父子关系
- 此时因为关注节点为父节点(p),经过左旋之后,它是原插入节点的左子树,所以进入情况
(4)
提前说明的是,这里假定父节点(p)是祖父节点(g)的左子树,所以在此情况下执行左旋
因为其父节点(p)左旋,则其右子树会变为原父节点(p)的父节点。
这里父节点(p)的右节点其实就是之前的关注节点,那么也就是将原关注节点作为原父节点(p)的父节点
因为此时我们的关注节点是父节点(p),父节点(p)经过左旋之后,自然成为插入节点的左子树。所以我们直接按照情况(4)进行调整,如下介绍情况(4)
如果插入节点属于父节点的左子树(4)
- 那么将关注节点的祖父节点(g)进行右旋
- 调整完成之后,关注节点的父节点(p)和兄弟节点(b)颜色互换
提前说明的是,这里假定父节点(p)是祖父节点(g)的左子树,所以在此情况下执行右旋
这里值得注意的是,将祖父节点(g)进行右旋之后,则祖父节点(g)和父节点(p)会断开,从而形成祖父节点(g)会成为父节点(p)的右子树。然后我们知道祖父节点(g)是黑色,父节点(p)是红色,那么右旋之后,形成的关系按照前序遍历是
父节点(p)--->关注节点(s)--->祖父节点(g)
其颜色状态如下
红(p)--->红(s)--->黑(g)
明显不满足红黑树的规则,所以就需要将父节点(p)的颜色红色和祖父节点(g)的黑色颜色互换,则颜色改变后如下:
黑(p)--->红(s)--->红(g)
最后根据叔叔节点相对于祖父节点的位置区分
根据之前的解析,我们确定的信息如下:
- 插入节点(s)是红色的
- 父节点(p)是红色的
- 叔叔节点(u)是黑色的
- 祖父节点(g)是黑色的
- 插入节点(s)位于父节点(p)的左子树情况已解析
- 插入节点(s)位于父节点(p)的右子树情况已解析
这个时候,我们发现,父节点(p)位于祖父节点(g)的左右情况并没有分析。而上面的情况(3)和(4)都假定了插入节点(s)的父节点(p)位于祖父节点(g)的左子树。而实际上父节点(p)相对于祖父节点(g)的关系既可能是左子树,也可能是右子树。所以出现如下情况:
如果父节点(p)位于祖父节点(g)的左子树
- 按照情况
(3)和(4)执行
如果父节点(p)位于祖父节点(g)的左子树
- 对于情况
(3),那么将关注节点设置为父节点(p)后,执行的是右旋 - 对于情况
(4),那么将关注节点设置为祖父节点(g)后,执行的是左旋,然后再染色
简化记忆
根据上面所有场景的介绍,为了方便记忆,本章以容易记忆的方式将场景简单列举出来,简化的场景如下
- 对黑色节点的插入无需操作
- 对红色节点的插入,如果叔叔节点(u)都是红色,想办法染色成黑色
具体染色操作是:将父节点(p)和叔叔节点(u)设置为黑色,并将祖父节点(g)设置为红色。然后将关注节点设置为祖父节点(g),向上递归,这样就把所有红黑树的叔叔节点(u)染色为黑色了 - 根据父节点(p)相对于祖父节点(g),插入节点(s)相对于父节点(p)的位置设置标号
具体标号操作是:从上往下的视角,如果父节点(p)在祖父节点(g)左边则记作L,右边记作R,插入节点(s)和父节点(p)的关系同理 - 如果是LL,则对祖父节点(g)右旋
- 如果是RR,则对祖父节点(g)左旋
- 如果是LR,则对父节点(p)左旋后,再按照LL操作给祖父节点(g)右旋
- 如果是RL,则对父节点(p)右旋后,再按照RR操作给祖父节点(g)左旋
进一步简化记忆,可以如下:
- 插入是红色才调整
- 如果叔叔是红色,则先染色
- 如果叔叔是黑色,根据LL/RR/LR/RL来执行操作
总结
至此,我们详细的了解了红黑树关于插入的操作步骤。并进一步的进行了简化记忆,接下来通过实验演示的方式验证所有的场景,下一个文章见
在学习cache的时候,有看到一系列的cache策略,这里汇总cache的策略,方便记忆
cache种类
cache分cacheable和non-cacheable
non-cacheable就是数据没有cache,而cacheable则又可以细分为如下
- read/write allocate
- write-back cacheable
- write-through cacheable
- shareability
分配策略
我们知道到数据miss的时候会分配cache line,那么主要有两种分配方式
- read allocation
读取操作miss时,分配一个cache line,并记录cache
- write allocation
写入操作miss时,分配一个cache line,并记录cache
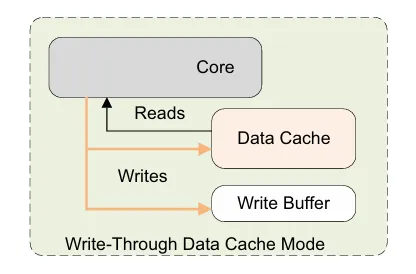
回写策略
数据更新也就是write的时候,cache对回写的策略如下
- write-back
写操作只会更新到cache,然后标记cache line为dirty,不会更新到内存中
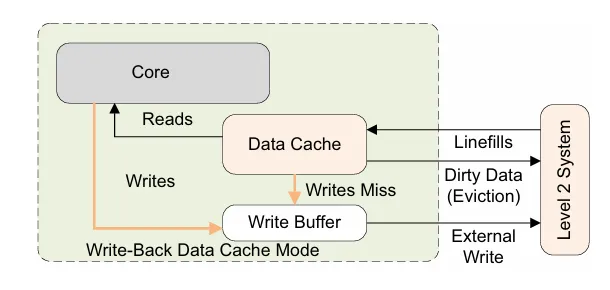
- write-through
写操作会直接更新到cache中,并同时更新到内存中
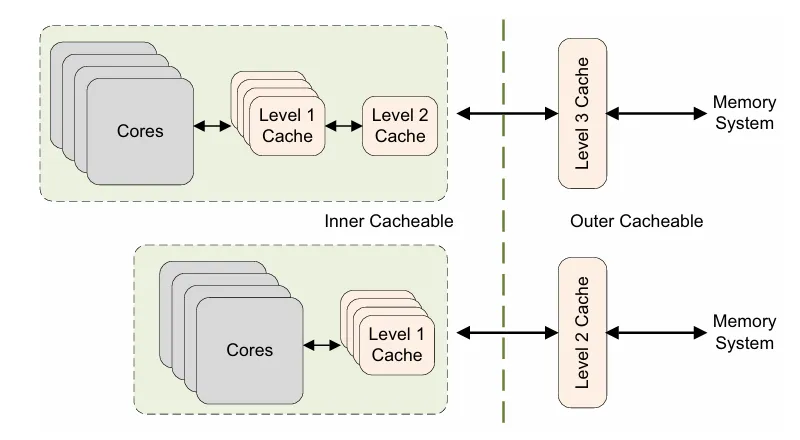
shareability
cache的共享属性分为 inner和outer,对于共享属性,我们可以这样记忆
- 对于每个cluster内部,cache是inner shareable属性的
- 两个cluster之间,cache是outer shareable属性的
cache可见性
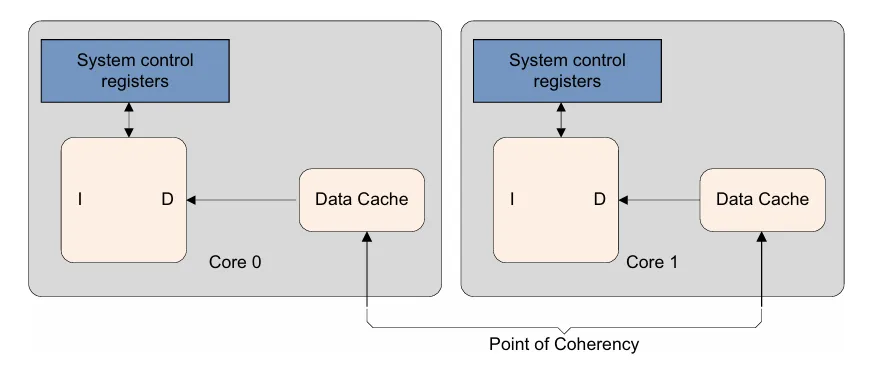
- PoU: point of unification : 对于inner share的cache,整个cluster内部看到的都是同一份cache的拷贝,不会出现两份不同的cache
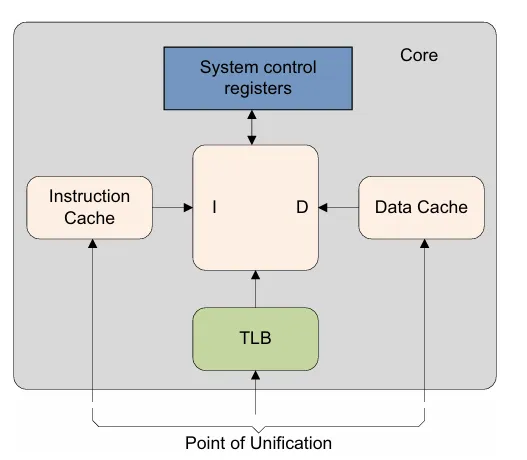
- PoC: point of coherency : 对于系统的硬件,如GPU,DMA,多个Cluster的CPU之间,看到的都是同一份cache的拷贝,不会出现两份不同的cache
操作系统在实现调度的时候会使用rb-tree,可见红黑树对于操作系统而言是多么的重要,本文首先介绍一下rb-tree的基本要素,后面连载逐渐了解rb-tree
树的结构
对于一个树的结构,默认的实现应该如下
struct Node { struct Node *left; /* left element */ struct Node *right; /* right element */ }
这里通过Node就是树的节点,left是树的左子树,right是树的右子树
此时我们新增一个parent的Node指针,这样我们可以查找树里面的元素就无需每次从根节点遍历,结构体如下
struct Node { struct Node *left; /* left element */ struct Node *right; /* right element */ struct Node *parent; /* parent element */ }
红黑树结构
对于红黑树,我们需要对Node添加颜色标识,可以如下
struct Node { struct Node *left; /* left element */ struct Node *right; /* right element */ struct Node *parent; /* parent element */ int rbe_color; /* node color */ }
这样,我们基本的红黑树的数据结构就完成了,接下来说明红黑树的特性
红黑树特性
对于红黑树的基本特性,主要是如下四点
- 根节点是黑色的
- 叶子节点都是黑色的,这里叶子节点包括最后一个null的节点(左右均null)
- 相邻的节点之间不能出现连续的红色
- 从根节点到叶子节点的黑色节点数目相等
这里以 Data Structure Visualizations 网站绘图
https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
下面展示一个从1-10共10个元素的红黑树图
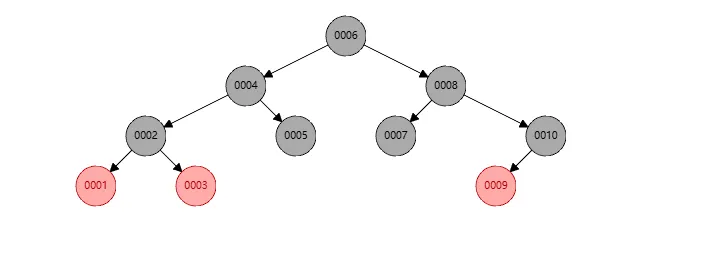
可以发现:
- 对于特性1,节点6是黑色的
- 对于特性2,图中我故意未画出
- 对于特性3,节点1,3,9并不连续
- 对于特性4,节点6,4,2和6,4,5和6,8,7和6,8,10的黑色节点数目相等
红黑树基本操作
红黑树的操作主要是左旋和右旋,以及插入和删除和搜索和染色,本文仅讨论左旋和右旋基本操作,插入,删除,搜索,染色等操作后面文章详细介绍。
关于左旋和右旋操作,是在红黑树出现不平衡的情况下,主动通过左旋和右旋调整使得整个红黑树平衡
左旋
对于左旋,就是红黑树不平衡的时候,对不平衡的节点向左旋转
假设有节点 x,y,a,b,r, 对其进行围绕x的左旋,如下所示
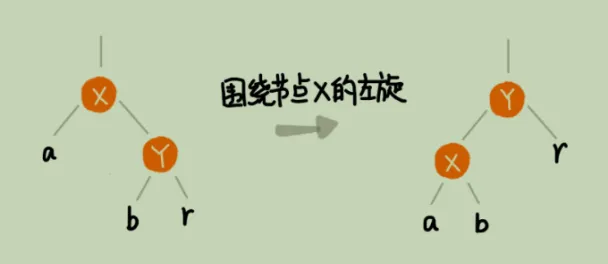
那么其具体步骤如下
- 将节点x的right断开
- 设置x的right节点y作为自己的parent
- 如果节点y有left节点,则将y的left设置为x的right
简单理解就是,基于谁的节点左旋,就是将那个节点的右节点作为自己的父节点,然后重建叶子节点
为了更清楚的了解左旋步骤,我基于最上面10个元素的示例演示,先删除了节点8,则此时的树结构如下
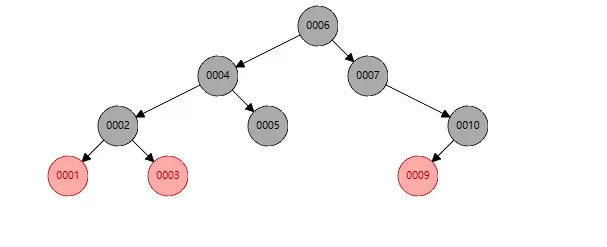
此时因为节点7没有左孩子,但是节点10有左孩子,这并不平衡,所以需要对节点10进行右旋,右旋我们还没解释,简单理解就是将自己的左孩子作为自己的父亲。所以右旋后结构如下
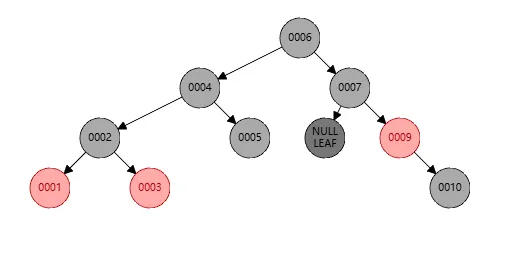
我们发现节点9不平衡,其左孩子的黑色个数是3,而其他个数是4,所以将其染色如下
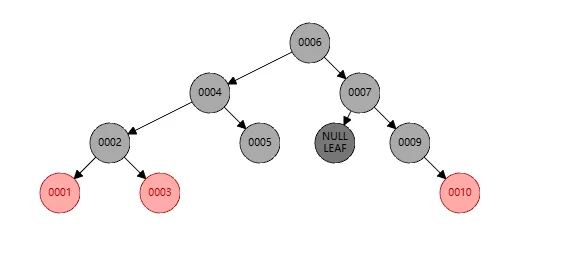
现在重点来了,但是此时节点7的左孩子是空,也就是其黑色节点数是3,我们需要左旋,步骤如下:
- 此时左旋的操作是针对节点7
- 对于7,断开节点9的连接,让其成为7的父节点
- 然后让节点7成为节点9的左孩子
- 因为节点9没有左孩子,所以无需进一步操作
这样左旋完成之后,结果如下
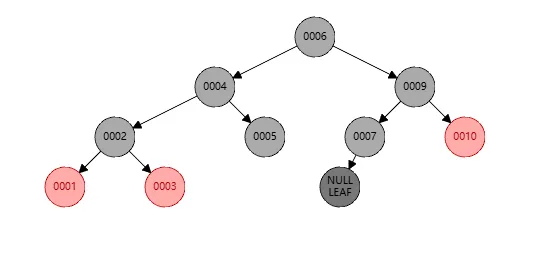
此时还是黑色个数不对,我们将节点10染色成黑色即可。如下
右旋
我们介绍了左旋,对于右旋,就是红黑树不平衡的时候,对不平衡的节点向右旋转
假设有节点 x,y,a,b,r, 对齐进行围绕x的右旋,如下所示

那么其具体步骤如下
- 将节点x的left断开
- 设置x的left节点y作为自己的parent
- 如果节点y有right节点,则将y的right设置为x的left
简单理解就是,基于谁的节点右旋,就是将那个节点的左节点作为自己的父节点,然后重建叶子节点
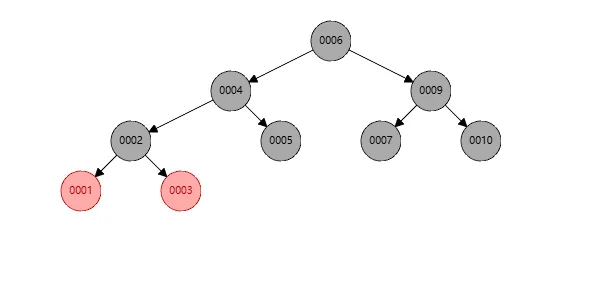
还是为了示例,还是基于上图删掉节点8之后的红黑树,此时我删除节点6,这里节点5会取代节点6,如下
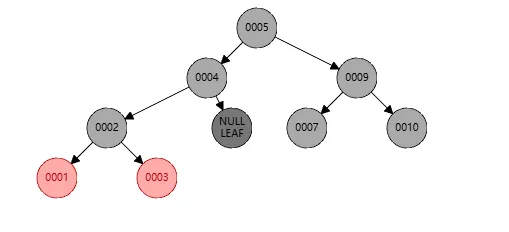
此时红黑树在节点4上不平衡了,我们需要针对节点4进行右旋
步骤如下:
- 此时左旋的操作是针对节点4
- 对于4,断开节点2的连接,让其成为4的父节点
- 然后让节点4成为节点2的右孩子
- 因为节点2有右孩子,所以将节点2的右孩子给节点4作为节点4的左孩子
这样右旋完成之后,结果如下
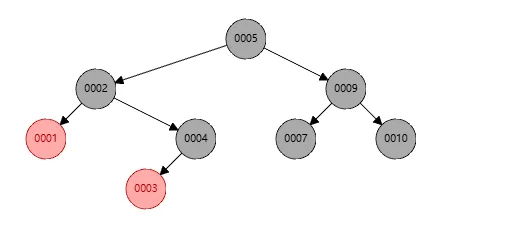
最后发现节点2的黑色节点不平衡,个数不对,所以将节点1染色成黑色即可完成,如下
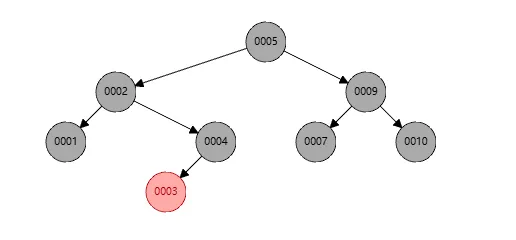
总结
本文作为红黑树介绍的开头,简单介绍了红黑树的基础,例如红黑树的特性,红黑树的左旋和右旋操作。
rtems不仅支持基于优先级调度的算法,也支持简单优先级调度算法,简单优先级算法相比于优先级调度算法而言减少了bitmap,直接通过优先级和队列FIFO特性来更新调度优先级。本文介绍rtems中简单优先级的实现方法
调度器结构体
我们通过_Scheduler_simple_Initialize函数可以知道此调度算法的结构体构造,如下
void _Scheduler_simple_Initialize( const Scheduler_Control *scheduler ) { Scheduler_simple_Context *context = _Scheduler_simple_Get_context( scheduler ); _Chain_Initialize_empty( &context->Ready ); }
首先,需要构造一个Scheduler_simple_Context结构体,其成员如下
typedef struct { /** * @brief Basic scheduler context. */ Scheduler_Context Base; /** * @brief One ready queue for all ready threads. */ Chain_Control Ready; } Scheduler_simple_Context;
可以发现,此结构体的上下文只包含了调度器上下文和一个链表,这个链表就是此调度算法的实现
我们知道此调度算法通过链表,所以需要初始化链表如下
static inline void _Chain_Initialize_empty( Chain_Control *the_chain ) { Chain_Node *head; Chain_Node *tail; _Assert( the_chain != NULL ); head = _Chain_Head( the_chain ); tail = _Chain_Tail( the_chain ); head->next = tail; head->previous = NULL; tail->previous = head; }
执行调度
对于基于队列的调度算法,其schedule函数就是将最高优先级的元素出队,如下
static inline Thread_Control *_Scheduler_simple_Get_highest_ready( const Scheduler_Control *scheduler ) { Scheduler_simple_Context *context = _Scheduler_simple_Get_context( scheduler ); return (Thread_Control *) _Chain_First( &context->Ready ); }
因为队列的FIFO结构,默认最高优先级的元素在队列头。所以直接从head->next拿即可。
阻塞任务
对于基于队列的调度算法,阻塞任务的方式就是从队列中解压出此任务,让其不在就绪队列中,如下
static inline void _Chain_Extract_unprotected( Chain_Node *the_node ) { Chain_Node *next; Chain_Node *previous; _Assert( !_Chain_Is_node_off_chain( the_node ) ); next = the_node->next; previous = the_node->previous; next->previous = previous; previous->next = next; #if defined(RTEMS_DEBUG) _Chain_Set_off_chain( the_node ); #endif }
任务就绪
对于基于队列的调度算法,任务就绪主要两个部分
- 将待插入的任务和就绪队列所有元素对比,找到小于等于的队列位置
- 插入队列
对于遍历就绪队列的代码如下
while ( next != tail && !( *order )( key, to_insert, next ) ) { previous = next; next = _Chain_Next( next ); }
这里的order就是根据遍历的元素,找到小于等于的队列位置,如下代码实现
static inline bool _Scheduler_simple_Priority_less_equal( const void *key, const Chain_Node *to_insert, const Chain_Node *next ) { const unsigned int *priority_to_insert; const Thread_Control *thread_next; (void) to_insert; priority_to_insert = (const unsigned int *) key; thread_next = (const Thread_Control *) next; return *priority_to_insert <= _Thread_Get_priority( thread_next ); }
根据上面的操作,可以找到待插入的位置,然后执行队列的插入操作即可
static inline void _Chain_Insert_unprotected( Chain_Node *after_node, Chain_Node *the_node ) { Chain_Node *before_node; _Assert( _Chain_Is_node_off_chain( the_node ) ); the_node->previous = after_node; before_node = after_node->next; after_node->next = the_node; the_node->next = before_node; before_node->previous = the_node; }
优先级更新
基于队列的优先级调度算法的更新优先级,主要如下操作
- 将待更新的任务取出
- 与任务就绪一致,找到队列中小于等于待更新优先级的位置
- 插入任务
- 执行调度
这里取出操作就是阻塞操作中的解压任务_Chain_Extract_unprotected
这里找到匹配的位置插入的操作和就绪任务一致
这里执行调度的操作就是让最高优先级的任务得以调度
总结
至此,我们完全了解的简单优先级调度算法的逻辑了,其相比于优先级调度算法而言,没有使用位图。设计更加简单,因为位图占用一定的内存资源,故此调度器算法内存占用少。而又因为位图的时间复杂度是O(1),遍历队列链表的复杂度是O(n)。
故简单优先级调度算法,减少了内存占用,牺牲了一些性能,比较适合非常简单的任务系统
在rtems中,可以通过region来分配内存,这样分配的内存可以独立于malloc申请的内存,从而实现内存区域的管理。本文基于此分享如何使用内存区域
一、作用
内存区域的作用是单独的内存区域,这个区域是固定的起始地址,大小和属性。使用内存区域的情况下,可以避免内存回收,内存规整等操作带来的性能消耗,同样的,也可以为多个任务创建不同的内存区域。
当然,在rtems中,如果分配内存区域的时候内存不足,也可以将任务进入等待队列,直到内存释放后有可用内存时。
二、代码实现
内存区域的代码如下
rtems_status_code rtems_region_create( rtems_name name, void *starting_address, uintptr_t length, uintptr_t page_size, rtems_attribute attribute_set, rtems_id *id ) { rtems_status_code return_status; Region_Control *the_region; if ( !rtems_is_name_valid( name ) ) { return RTEMS_INVALID_NAME; } if ( id == NULL ) { return RTEMS_INVALID_ADDRESS; } if ( starting_address == NULL ) { return RTEMS_INVALID_ADDRESS; } the_region = _Region_Allocate(); if ( !the_region ) return_status = RTEMS_TOO_MANY; else { _Thread_queue_Object_initialize( &the_region->Wait_queue ); if ( _Attributes_Is_priority( attribute_set ) ) { the_region->wait_operations = &_Thread_queue_Operations_priority; } else { the_region->wait_operations = &_Thread_queue_Operations_FIFO; } the_region->maximum_segment_size = _Heap_Initialize( &the_region->Memory, starting_address, length, page_size ); if ( !the_region->maximum_segment_size ) { _Region_Free( the_region ); return_status = RTEMS_INVALID_SIZE; } else { the_region->attribute_set = attribute_set; *id = _Objects_Open_u32( &_Region_Information, &the_region->Object, name ); return_status = RTEMS_SUCCESSFUL; } } _Objects_Allocator_unlock(); return return_status; }
2.1 解析形参
name:内存区域名称
starting_address:需要申请的内存地址
length:内存区域大小
page_size: 设置内存区域的页大小
attribute_set: 设置内存的调度属性
id: 内存区域id
2.2 内存管理线程
rtems提供两种线程方式:一个是fifo,也就是先进先出调度,另一个是priority,也就是基于优先级的调度,分别如下:
const Thread_queue_Operations _Thread_queue_Operations_FIFO = { .priority_actions = _Thread_queue_Do_nothing_priority_actions, .enqueue = _Thread_queue_FIFO_enqueue, .extract = _Thread_queue_FIFO_extract, .surrender = _Thread_queue_FIFO_surrender, .first = _Thread_queue_FIFO_first }; const Thread_queue_Operations _Thread_queue_Operations_priority = { .priority_actions = _Thread_queue_Priority_priority_actions, .enqueue = _Thread_queue_Priority_enqueue, .extract = _Thread_queue_Priority_extract, .surrender = _Thread_queue_Priority_surrender, .first = _Thread_queue_Priority_first };
这个初始化的线程,会在内存不足的时候阻塞。
2.3 申请堆
通过_Heap_Initialize直接申请堆作为内存区域的Memory成员。地址指向starting_address
2.4 设置属性和申请id
对于这块内存,可以设置region结构体的属性字段,并通过_Objects_Open_u32申请内存区域id。region结构体如下
typedef struct { Objects_Control Object; Thread_queue_Control Wait_queue; /* waiting threads */ const Thread_queue_Operations *wait_operations; uintptr_t maximum_segment_size; /* in bytes */ rtems_attribute attribute_set; Heap_Control Memory; } Region_Control;
三、测试分配内存
测试分配内存区域非常简单,我们可以直接通过rtems_region_create分配即可,如下:
static const rtems_name name = rtems_build_name('K', 'Y', 'L', 'I'); #define CONFIGURE_MAXIMUM_REGIONS 1 static void test_region_create(void) { rtems_status_code sc; rtems_id id; void *seg_addr1; void *seg_addr2; sc = rtems_region_create( name, 0x4000000, 640, 16, RTEMS_DEFAULT_ATTRIBUTES, &id ); printf( "sc=%d\n", sc); sc = rtems_region_get_segment( id, 32, RTEMS_DEFAULT_OPTIONS, RTEMS_NO_TIMEOUT, &seg_addr1 ); printf( "sc=%d seg_addr=%p\n", sc, seg_addr1); sc = rtems_region_get_segment( id, 32, RTEMS_DEFAULT_OPTIONS, RTEMS_NO_TIMEOUT, &seg_addr2 ); printf( "sc=%d seg_addr=%p\n", sc, seg_addr2); sc = rtems_region_return_segment( id, seg_addr1); printf( "sc=%d\n", sc); sc = rtems_region_return_segment( id, seg_addr2); printf( "sc=%d\n", sc); }
3.1 region个数
默认情况下,需要通过一个宏设置内存区域个数CONFIGURE_MAXIMUM_REGIONS,这里定义多少就代表系统最多可以申请多少region
3.2 最小申请大小
内存区域最小分配为64字节,准确来说是大于等于52字节,这样内存区域才能正常工作。否则rtems_region_create返回无效
3.3 获取内存
通过rtems_region_get_segment可以获取region的段,这样就能直接使用region
3.4 释放内存到内存
通过rtems_region_get_segment可以释放region的段,这样下一个程序可以重新分配
3.5 测试程序内存布局
内存布局如下
(gdb) x/14g 0x4000000 0x4000000: 0x0000000004000280 0x0000000000000031 0x4000010: 0x0000000004000060 0x0000000000105d68 0x4000020: 0x0000000000000000 0x0000000000000000 0x4000030: 0x0000000000000030 0x0000000000000030 0x4000040: 0x0000000000105d68 0x0000000000105d68 0x4000050: 0x0000000000000000 0x0000000000000000 0x4000060: 0x0000000000000000 0x0000000000000211
从heap block结构体可以看到,内存分配一切正常
四、总结
通过上述的实验,可以清楚的了解到rtems的region的分配和原理。这里分配固定地址上的内存块,供程序使用
