目录
在开发高性能的C程序的时候,经常使用环形缓冲区,我们生活中常见的使用环形缓冲区的例子就是声卡。本文介绍如何开发环形缓冲区
Circular buffer
首先我们看个动画
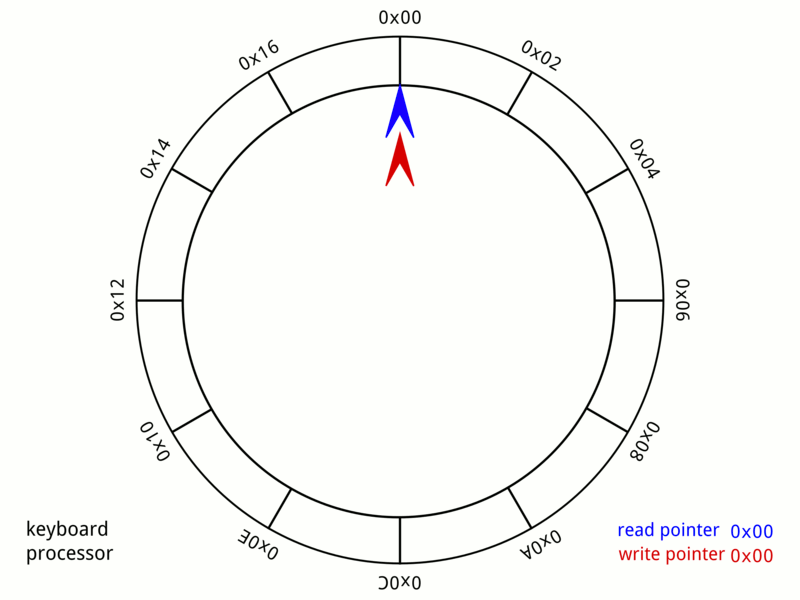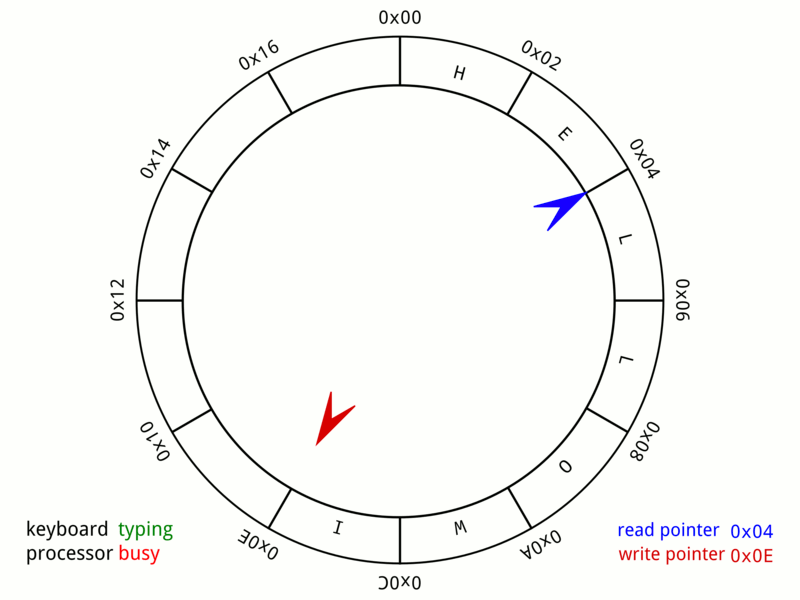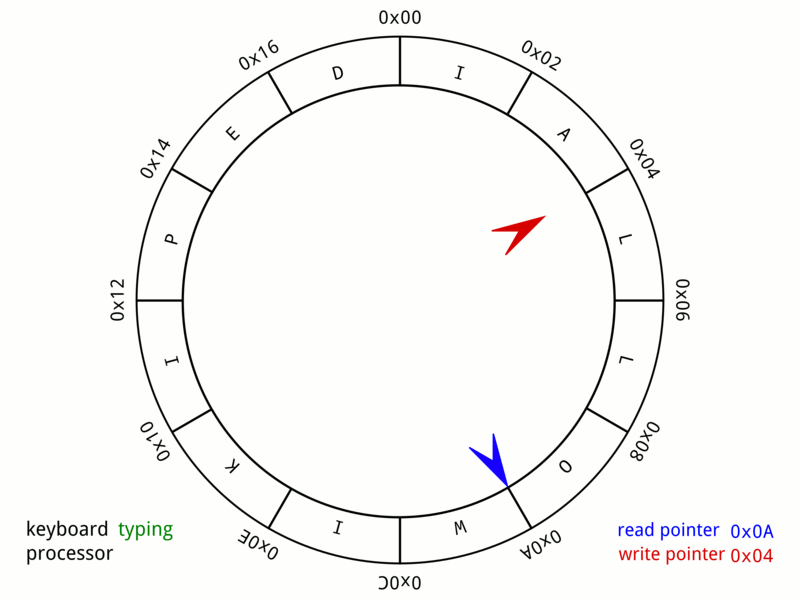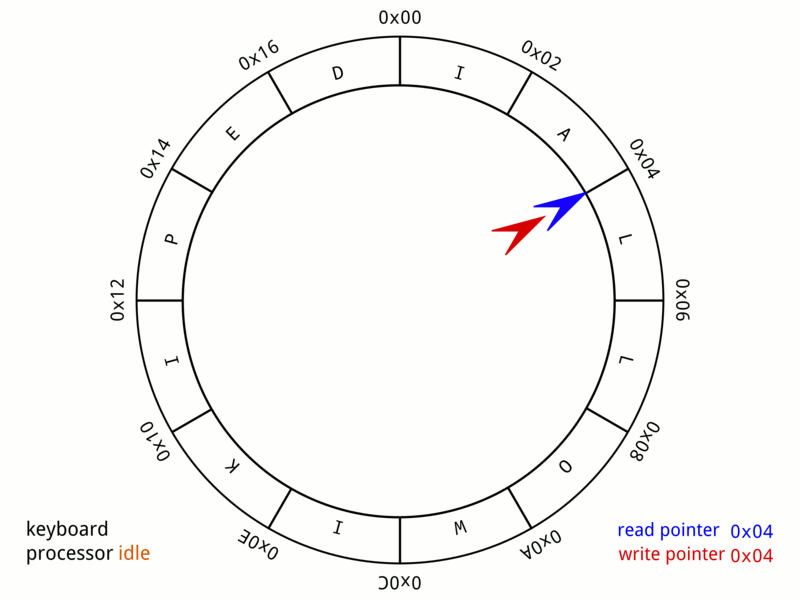
读写指针一直在环中打转,如果写指针追上读指针的时候,相当于环形缓冲区的内容消耗完毕,那么程序将等待。
在生活的例子中就是我们听到的声音卡在这里了,如果体现到声卡的行为上,如果是存在bug,那就是underrun,也就是pcm没办法从应用层获取数据,使得驱动的ringbuffer空了,声卡“饿晕”了。
如果以生活的成语来说,就是赛跑游戏
原理
首先启动的时候,buffer是空的,如下
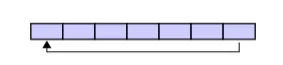
当put第一个数据的时候,可以是buffer的任意位置
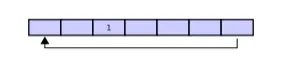
当继续put数据的时候,那么会跟在第一个数据的位置后面,因为tail指针会移动
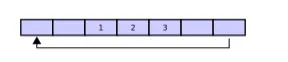
如果get数据的时候,buffer默认构造成FIFO结构,所以先来先服务,head指针会移动

长此以往,buffer可能一直在赛跑状态,也有可能是buffer 满的状态,如下

如果buffer满的时候,还是不断的put数据进去,那么tail指针会覆盖原来的位置的数据,它们是形成环的。 假设在buffer满的时候,get指针不动的前提上,put了A和B,那么A和B就会覆盖原来的数据3和4
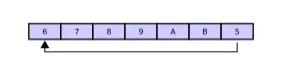
在这种情况下,如果get指针获取了两个元素,因为get指针来自head,所以实际上获取的数据是5和6,因为此时5和6是最老的数据
测试程序
实现环形缓冲区有四大因素,如下
- buffer start
- buffer size
- write buffer index
- read buffer index
例如如下
struct ring_buffer { void *addr; uint32_t size; uint32_t head; uint32_t tail; }
这里有一个最简单的ringbuffer示例,如下
#include <stdio.h> enum { N = 10 }; // size of circular buffer int buffer [N]; // note: only (N - 1) elements can be stored at a given time int writeIndx = 0; int readIndx = 0; int put (int item) { if ((writeIndx + 1) % N == readIndx) { // buffer is full, avoid overflow return 0; } buffer[writeIndx] = item; writeIndx = (writeIndx + 1) % N; return 1; } int get (int * value) { if (readIndx == writeIndx) { // buffer is empty return 0; } *value = buffer[readIndx]; readIndx = (readIndx + 1) % N; return 1; } int main () { // test circular buffer int value = 1001; while (put (value ++)); while (get (& value)) printf ("read %d\n", value); return 0; }
编译运行如下
read 1001 read 1002 read 1003 read 1004 read 1005 read 1006 read 1007 read 1008 read 1009
高性能优化
其实根据上面的测试代码的writeIndx = (writeIndx + 1) % N;可以看到,每次判断index的时候用到了取余操作,这在C语言世界是非常低效的。因为CPU对于取余来说指令非常耗时。所以这是第一个优化点
其次,普通实现的环形缓冲区会出现多次拷贝,如下
uint32_t circular_buffer_write(struct ring_buffer *rb, void *buf, uint32_t count) memcpy(rb->addr + rb->tail, buf, size); if(size < count){ memcpy(rb->addr, buf + size, count - size); } rb->tail = (rb->tail + count) % rb->size; return count; }
可以看到,如果按照普通的实现,ringbuffer在边界上需要处理两次memcpy,这是第二个优化点
解决这两个优化点有什么办法呢?
我们回到现代CPU设计的 虚拟内存和物理内存的概念上,现代CPU设计的时候,可以将一个物理地址分别由两个虚拟地址映射,也就意味着,如果我实际操作的是一个物理地址 0x1000-0x2000,但是我申请了两个连续的虚拟地址 0xffff1000-0xffff2000和0xffff2000-0xffff3000。这里0xffff1000-0xffff2000和0xffff2000-0xffff3000都是映射在同一个物理地址范围0x1000-0x2000。
那么ringbuffer就可以同时解决上述两个点的优化项
- 不需要通过取模指令计算边界,直接index超越边界即可,超越边界实际上物理地址已经成环,我们只需要时候通过减法调整回边界,如
head -= BUFFER_SIZE;或者tail -= BUFFER_SIZE; - 不需要两次memcpy调用,直接省掉一次memcpy的调用可以搞定。
总结
本文介绍环形缓冲区的设计和优化方法,这在开发高性能程序过程中至关重要。这种优化项利用了现代操作系统特性做的取巧,可以获得不错的程序性能提升,而且方案成熟。