目录
在<调度(4)-CFS调度器和权重>介绍了CFS的核心点之一,weight.通过配置weight的数组,可以粗略的等比计算nice,而vruntime的实际步长就是通过weight来计算的.
同样的,在<调度(3)-调度器的设计>我们提到,cfs有大量的启发式计算,同样的,对于weight,为了维护cfs的公平性问题,会在enqueue/dequeue的时候,重新计算权重,也就是reweight,今天来简单了解一下cfs的reweight
reweight的作用
reweight的作用是让sched_entity能根据本地负载动态调整权重,避免某个CPU过载而其他CPU空闲时出现不公平,其关键在于任务的enqueue和dequeue,如下 enqueue流程
enqueue_task_fair update_cfs_group calc_group_shares reweight_entity
dequeue流程
dequeue_task_fair update_cfs_group calc_group_shares reweight_entity
可以看到,这里的核心函数函数reweight_entity
reweight_entity
static void reweight_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, unsigned long weight) { if (se->on_rq) { /* commit outstanding execution time */ if (cfs_rq->curr == se) update_curr(cfs_rq); update_load_sub(&cfs_rq->load, se->load.weight); } dequeue_load_avg(cfs_rq, se); update_load_set(&se->load, weight); #ifdef CONFIG_SMP do { u32 divider = get_pelt_divider(&se->avg); se->avg.load_avg = div_u64(se_weight(se) * se->avg.load_sum, divider); } while (0); #endif enqueue_load_avg(cfs_rq, se); if (se->on_rq) update_load_add(&cfs_rq->load, se->load.weight); }
简单分析一下其内容
- if (cfs_rq->curr == se) update_curr(cfs_rq); 如果就是当前se,则更新vruntime一次
- update_load_sub : 减去当前任务在cfs上的load
- dequeue_load_avg : 将当前se的load从cfs的load_avg中移除
- update_load_set: 设置新权重
- se->avg.load_avg = div_u64(se_weight(se) * se->avg.load_sum, divider);: 用新的权重通过PELT重新计算负载
- enqueue_load_avg : 计算好了load_avg,入队
- update_load_add: 将其新的权重值加到当前总负载
reweight_task
除了enqueue和dequeue,其他所有场景设置权重可以通过对外api,reweight_task完成,reweight_task是 reweight_entity 的封装,如下
void reweight_task(struct task_struct *p, const struct load_weight *lw) { struct sched_entity *se = &p->se; struct cfs_rq *cfs_rq = cfs_rq_of(se); struct load_weight *load = &se->load; reweight_entity(cfs_rq, se, lw->weight); load->inv_weight = lw->inv_weight; }
其流程如下
sched_fork # fork时 set_user_nice # set nice时 __setscheduler_params # posix api时 set_load_weight scale_load reweight_task
calc_group_shares
我们留意到update_cfs_group会调用calc_group_shares,它的作用是真正的计算权重的地方,值得注意的是,这里权重在计算的时候叫做shares,其代码如下
/* * All this does is approximate the hierarchical proportion which includes that * global sum we all love to hate. * * That is, the weight of a group entity, is the proportional share of the * group weight based on the group runqueue weights. That is: * * tg->weight * grq->load.weight * ge->load.weight = ----------------------------- (1) * \Sum grq->load.weight * * Now, because computing that sum is prohibitively expensive to compute (been * there, done that) we approximate it with this average stuff. The average * moves slower and therefore the approximation is cheaper and more stable. * * So instead of the above, we substitute: * * grq->load.weight -> grq->avg.load_avg (2) * * which yields the following: * * tg->weight * grq->avg.load_avg * ge->load.weight = ------------------------------ (3) * tg->load_avg * * Where: tg->load_avg ~= \Sum grq->avg.load_avg * * That is shares_avg, and it is right (given the approximation (2)). * * The problem with it is that because the average is slow -- it was designed * to be exactly that of course -- this leads to transients in boundary * conditions. In specific, the case where the group was idle and we start the * one task. It takes time for our CPU's grq->avg.load_avg to build up, * yielding bad latency etc.. * * Now, in that special case (1) reduces to: * * tg->weight * grq->load.weight * ge->load.weight = ----------------------------- = tg->weight (4) * grp->load.weight * * That is, the sum collapses because all other CPUs are idle; the UP scenario. * * So what we do is modify our approximation (3) to approach (4) in the (near) * UP case, like: * * ge->load.weight = * * tg->weight * grq->load.weight * --------------------------------------------------- (5) * tg->load_avg - grq->avg.load_avg + grq->load.weight * * But because grq->load.weight can drop to 0, resulting in a divide by zero, * we need to use grq->avg.load_avg as its lower bound, which then gives: * * * tg->weight * grq->load.weight * ge->load.weight = ----------------------------- (6) * tg_load_avg' * * Where: * * tg_load_avg' = tg->load_avg - grq->avg.load_avg + * max(grq->load.weight, grq->avg.load_avg) * * And that is shares_weight and is icky. In the (near) UP case it approaches * (4) while in the normal case it approaches (3). It consistently * overestimates the ge->load.weight and therefore: * * \Sum ge->load.weight >= tg->weight * * hence icky! */ static long calc_group_shares(struct cfs_rq *cfs_rq) { long tg_weight, tg_shares, load, shares; struct task_group *tg = cfs_rq->tg; tg_shares = READ_ONCE(tg->shares); load = max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg); tg_weight = atomic_long_read(&tg->load_avg); /* Ensure tg_weight >= load */ tg_weight -= cfs_rq->tg_load_avg_contrib; tg_weight += load; shares = (tg_shares * load); if (tg_weight) shares /= tg_weight; /* * MIN_SHARES has to be unscaled here to support per-CPU partitioning * of a group with small tg->shares value. It is a floor value which is * assigned as a minimum load.weight to the sched_entity representing * the group on a CPU. * * E.g. on 64-bit for a group with tg->shares of scale_load(15)=15*1024 * on an 8-core system with 8 tasks each runnable on one CPU shares has * to be 15*1024*1/8=1920 instead of scale_load(MIN_SHARES)=2*1024. In * case no task is runnable on a CPU MIN_SHARES=2 should be returned * instead of 0. */ return clamp_t(long, shares, MIN_SHARES, tg_shares); }
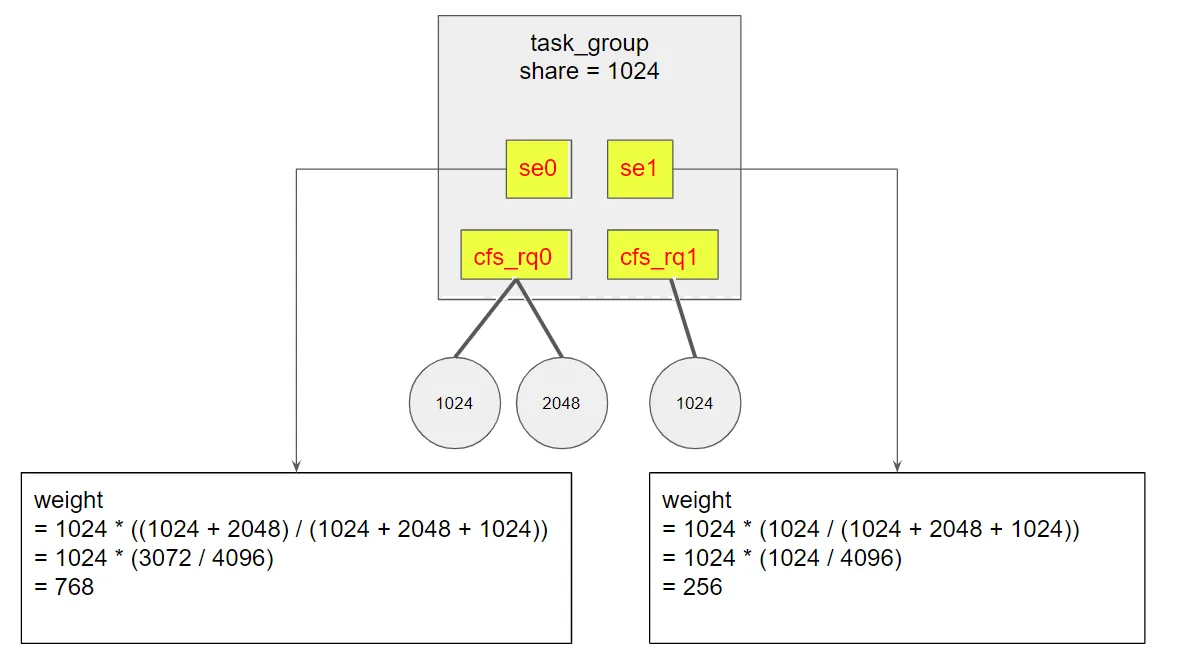
首先,我们知道task_group记录了组的本身权重shares,如下
struct task_group { unsigned long shares; }
按组分配的所有任务会按照比例分配这个shares值,举个例子
- 两个CPU,每个CPU有自己的se,分别是se0,se1
- CPU0上有两个任务,权重分别是1024,2048
- CPU1上有一个任务,权重是1024
那么se0上分配的比例是(1024+2048)/((1024+2048)+1024),而se1上分配的比例是1024/((1024+2048)+1024)
对于代码,分析如下
- max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg); 取当前瞬时权重和PELT的平均权重的较大的那个
- tg_weight -= cfs_rq->tg_load_avg_contrib; 将当前组的权重减去本CPU之前贡献的旧值
- tg_weight += load; 再加上上述的max值
- shares = (tg_shares * load); 总份额是share值乘以上述的max
- shares /= tg_weight; 然后除以计算后的权重
可以看到,这其实是一个这样的公式
load = max(grq->load.weight, grq->avg.load_avg) tg_weight = tg->load_avg - grq->tg_load_avg_contrib + load; shares = tg->shares * load / tg_weight
整合一下
shares = tg->shares * max(grq->load.weight, grq->avg.load_avg) / (tg->load_avg - grq->avg.load_avg + max(grq->load.weight, grq->avg.load_avg))
其实就是注释的最后公式

回顾注释
Step 1: 理想公式
* tg->weight * grq->load.weight * ge->load.weight = ----------------------------- (1) * \Sum grq->load.weight
首先,我们分配一个实际任务的weight理论上是这个组的shares,也就是tg->shares,但是如果直接设置这个值,那么实际上并不公平.
为了维护公平性原则,我们为一个任务分配的weight应该将shares值按照实际负载来估计,所以理论想法是
weight = shares * (当前CPU负载 / 组内所有CPU负载)
这相当于维护了任务的局部公平性原则, 也就是按照当前真实负载比例来切分shares,而不是直接用shares
Step 2: 平均负载替换瞬时负载
* tg->weight * grq->avg.load_avg * ge->load.weight = ------------------------------ (3) * tg->load_avg
但是计算组内所有的CPU负载的代价比较高,我们需要一定的启发式计算,方法是将PELT计算的平均负载来替代CPU负载,也就是如下
grq->load.weight -> grq->avg.load_avg
这样就不需要反复计算组内任务的CPU负载,而是直接从PELT中取平均负载,那么对于当前CPU的平均负载为grq->avg.load_avg,而组内所有CPU的平均负载是tg->load_avg
那么这次等效替换的计算公式变更为
weight = shares * (当前CPU平均负载 / 组内所有CPU平均负载)
这样近似计算在负载比较平稳的时候效果很好,且计算成本很低。
Step 3: 取平均负载和瞬时负载最大值
* tg->weight * grq->load.weight * --------------------------------------------------- (5) * tg->load_avg - grq->avg.load_avg + grq->load.weight
我们看看这个将瞬时负载到平均负载的等效计算带来的负面效果:假设当前CPU下比较空闲的时候,一个新的任务诞生,那么平均负载会变化的很慢,所以Step 2的公式近似为
weight = shares * (当前CPU平均负载(趋于0) / 组内所有CPU平均负载(较大值))
那么此时这个新的任务分到的weight远比预设的shares值小. 这是问题1
再假设另一种情况,当前CPU有负载,其他任务全部空闲,那么Step 2的公式近似为
weight = shares * (当前CPU平均负载(较大值) / 组内所有CPU平均负载(趋于0))
这种情况下,任务分到的weight又因为组内所有CPU平均负载趋于0,导致远远大于shares.这是问题2
为了解决上面问题,需要为公式计算一次当前CPU上的瞬时负载,然后拿这个瞬时负载和当前CPU的平均负载取较大值,也就是max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg);我们把这个值记作当前CPU的负载:cfs_rq->load.weight = max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg)
我们拿cfs_rq->load.weight作为分子,而总负载拿所有CPU平均负载减去当前CPU的平均负载,再加上cfs_rq->load.weight,此时公式为
weight = shares * ((当前CPU平均负载和瞬时负载的最大值) / (组内所有CPU平均负载 - 当前CPU平均负载 + 当前CPU瞬时负载))
到这里,计算一个任务的reweight的公式完成了.
总结
本文介绍了reweight的作用,其也是cfs为了维护局部公平性的一种手段,当任务入队出队以及其他场景中,都需要重新计算权重,而权重的公式是将预设的shares值,按照理论想法根据负载比例分配.
最后计算方式实际上是按照平均负载的方式计算,我们回顾此公式
shares = tg->shares * max(grq->load.weight, grq->avg.load_avg) / (tg->load_avg - grq->avg.load_avg + max(grq->load.weight, grq->avg.load_avg))
这里稍微留意一下这个比例
max(grq->load.weight, grq->avg.load_avg) / (tg->load_avg - grq->avg.load_avg + max(grq->load.weight, grq->avg.load_avg))
因为一个瞬态负载的值往往大于平均值,也就意味着这个比值是大于1的,也就是如下
shares = tg->shares * (>1)
也就是
shares > tg->shares
也就是一个任务reweight的时候,往往比预设的组的shares更大,在<调度(4)-CFS调度器和权重>的计算公式vruntime += delta * nice0 / weight,weight越大则vruntime变化越小,那么长期来看任务的reweight,它其实获得的时间片反而越多,但其响应越快
也就是说,虽然reweight为了局部的公平性设计了这个公式,但实际上仔细分析此公式也是存在不公平的,一个任务不断的reweight,那么其weight越大,weight越大,那么它的vruntime变化越小,vruntime预估变化小,那么其任务获得的时间片越多,也就导致了任务被偏心的分配了更多的时间来运行,加强了其响应能力,但是局部的不公平还是存在的.
举个生活的例子,生日了分蛋糕,作为家长,最初的愿望是想平分蛋糕,但是有些小孩是饿哭来要蛋糕的,有些小孩是后面才来要蛋糕的,此时分配的蛋糕默认给饿哭的孩子多分了一点,为了不让饿哭的小孩吃了还饿,主观性的多分了一点蛋糕,那么实际上对其他小孩而言是少了蛋糕, 但是其他小孩并不会因为少一点蛋糕而饿哭,虽然这种微小局部的不公平仍然存在,但是我们没必要追求这个颗粒度上的完全公平了.
因为"满足爱哭小孩有糖吃"定理更重要