目录
EEVDF(Earliest Eligible Virtual Deadline First)为了解决上文中CFS的无法低延时的痛点而诞生的。它在保持 CFS 公平性的基础上,引入了“虚拟截止期限”和“lag”概念,让调度器既能公平分配资源,又能显著降低延迟。 本文就来详细拆解 EEVDF 的核心思路,以及它如何通过 latency-nice 值优雅平衡吞吐与响应。
Lag
所谓lag,我们可以简单理解为欠条,谁欠得最多(lag 正值最大)谁最先玩
假设 5 个进程共享一个 CPU,nice 值相同。 理想情况下,每秒每个进程应该得到 200ms CPU 时间。 但实际运行中,由于中断、抢占、迁移等原因,每个进程得到的真实时间会有偏差。 EEVDF 把这个偏差定义为 lag:
lag = 理想时间 - 实际获得时间
- lag > 0:进程“欠债”了,得到的 CPU 时间比应得的少 → 应该优先调度
- lag < 0:进程“超支”了,得到的 CPU 时间比应得的多 → 应该降低优先级
- lag = 0:正好公平
只有 lag ≥ 0 的进程才“eligible”(有资格被调度)。 lag < 0 的进程要等到时间继续前进、它的“应得时间”赶上“已得时间”后,才重新 eligible。这段时间差叫 eligible time。简单来说:EEVDF 通过 lag 实时追踪每个进程的“公平欠账”,让“欠得最多”的进程最先上场。
Virtual deadline
这个很好理解,EDF调度通过实际deadline来判断截止时间,EEVDF通过虚拟截止时间来判断,EEVDF挑选 virtual deadline 最早的进程。
virtual deadline 的计算公式:
virtual deadline = eligible time + time slice
- eligible time:进程从不 eligible 到重新 eligible 所需的时间(基于 lag 追赶)
- time slice:本次分配的时间片(类似 CFS 的 sched_slice)
这里time slice的关键在于latency-nice的影响,主要如下:
- latency-nice 低(延迟敏感):time slice 短 → virtual deadline 早 → 优先级高
- latency-nice 高(延迟不敏感):time slice 长 → virtual deadline 晚 → 优先级低
如下图
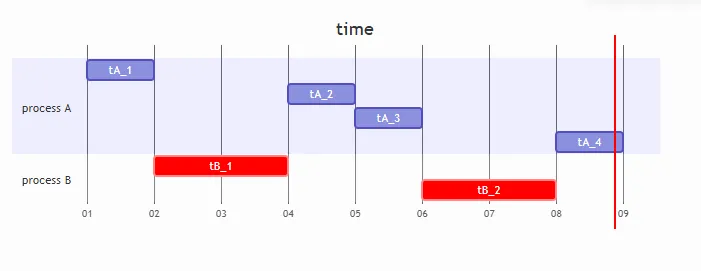
两个程序A和B,我们留意到A是属于latency-nice 低,time slice 短的程序,B就是latency-nice 高,time slice 长的程序,他们调度的特性就是,让延迟敏感的程序优先运行,但是切的更短。而实际上,A和B的运行时间是一致的。
这种将延迟敏感任务分成很多小片段,频繁调度的办法,换来的低延迟,而对延迟不敏感的任务,分成长片段,换来的是高吞吐,所以这完美解决了 CFS 的痛点:nice 值只管“总量”,latency-nice 可以管“响应速度”。
回到virtual deadline 的概念,我们如果latency-nice 低,那么virtual deadline低,这样也就越低延迟
在EEVDF中,可以通过sched_runtime设置一个自定义的time slice,这样用户的可操作性更强。但是需要注意关键点
- time slice小,抢占多,低延迟
- time slice大,吞吐高,延迟高
如果设置这个值,其范围是
0.1ms - 100ms
当然,如果不设置这个值,就是内核默认的经验值,和cfs的sysctl_sched_min_granularity一致,为sysctl_sched_base_slice。
其默认值为
- 0.70 msec * (1 + ilog(ncpus))
unsigned int sysctl_sched_base_slice = 700000ULL; /* * Increase the granularity value when there are more CPUs, * because with more CPUs the 'effective latency' as visible * to users decreases. But the relationship is not linear, * so pick a second-best guess by going with the log2 of the * number of CPUs. * * This idea comes from the SD scheduler of Con Kolivas: */ static unsigned int get_update_sysctl_factor(void) { unsigned int cpus = min_t(unsigned int, num_online_cpus(), 8); unsigned int factor; switch (sysctl_sched_tunable_scaling) { case SCHED_TUNABLESCALING_NONE: factor = 1; break; case SCHED_TUNABLESCALING_LINEAR: factor = cpus; break; case SCHED_TUNABLESCALING_LOG: default: factor = 1 + ilog2(cpus); break; } return factor; } static void update_sysctl(void) { unsigned int factor = get_update_sysctl_factor(); #define SET_SYSCTL(name) \ (sysctl_##name = (factor) * normalized_sysctl_##name) SET_SYSCTL(sched_base_slice); #undef SET_SYSCTL }
假设系统有 8 个核,那么 factor=4,最终的 base_slice 就为 0.70ms * 4 = 2.8ms
调度周期
- 在 EEVDF 的情况下,调度周期 P 的计算方法如下:
W是所有任务的权重累计- s_i 是任务
i的时间片(slice) - w_i 是任务
i的权重(weight)
P_max = W * max(s_i / w_i)
- 对于某个特定任务
i的平均周期 Pi 是:
P_i = W * (s_i / w_i)
- 由此可见,整个 EEVDF 的调度周期,也是所有任务中平均调度周期最大的那个任务的平均调度周期。
- 每个任务公平地获得调度周期中的如下时间:
S_i = P * (w_i / W)
总结
CFS为了公平去实现公平,最终陷入了公平,而EEVDF为了延迟去实现低延迟,目前来看,其是EDF的Linux推广版,我们可以从解决问题的角度思考为何如此演进。
一个任务在OS上调度,你究竟要的是公平,还是要的是更低延迟的运行。
公平是一个虚幻的概念,而低延迟是目标体验。所以linux从CFS转移到EEVDF也就意味着,调度应该为了解决实际问题为根本点考虑,而不是为了理论公平,理论响应度最高来考虑设计。
当然,EEVDF可能因为低时延牺牲一定的高响应,最终取舍还是看实际OS产品落地的程序员